【爬虫2】迈出吃公粮的第一步
用requests和re,爬取网站信息。在一定程度上促进了学者进局子吃公粮
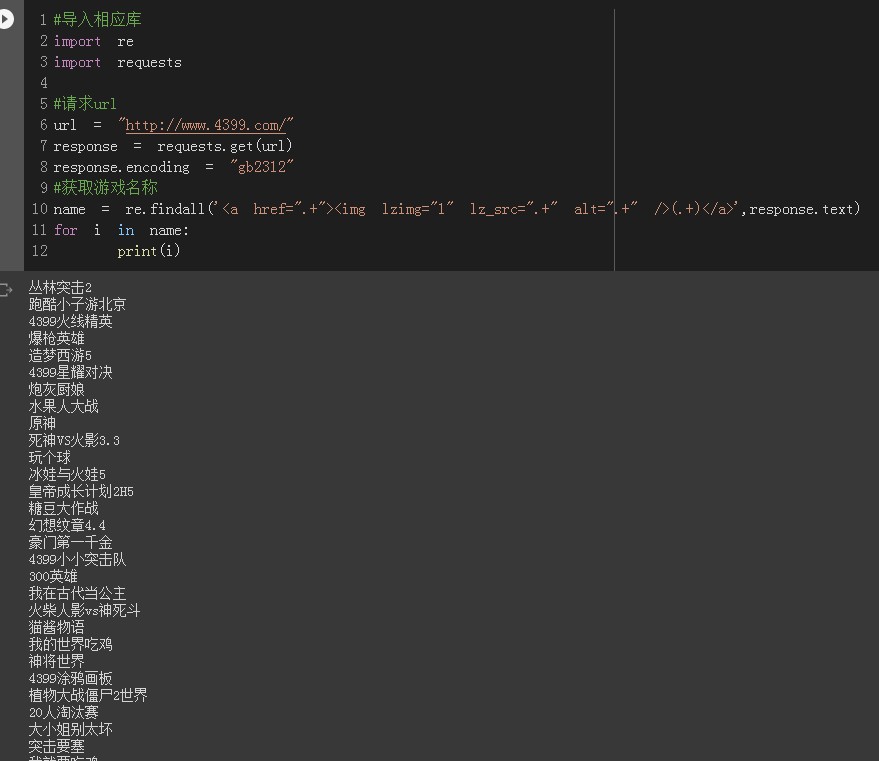
请求URL
import requests #导入相应库 url = "http://bbs.qyai.net/" response = requests.get(url) #get请求url response = response.text #获取url的html print(response) #输出获取html
如图所示
也有可能出现乱码
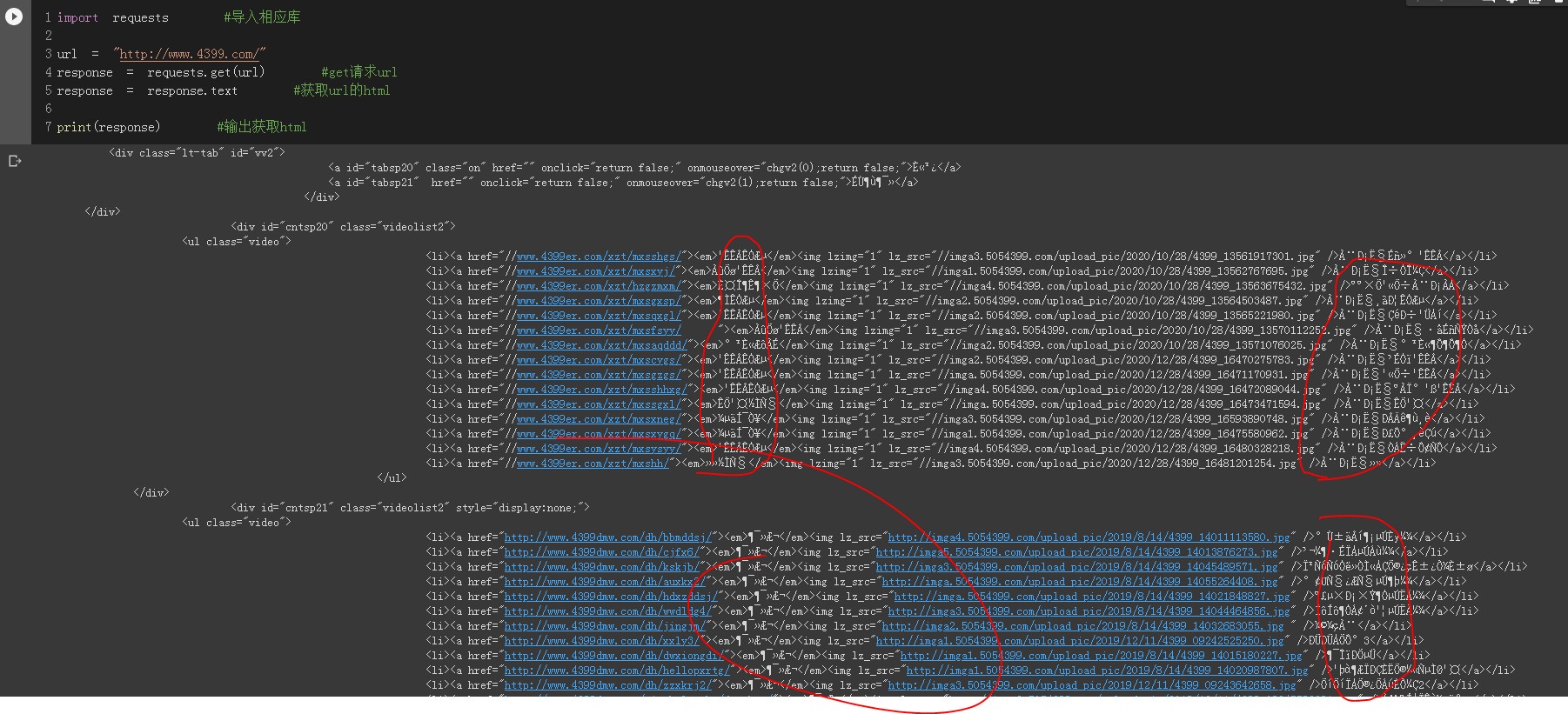

查看网站html开头
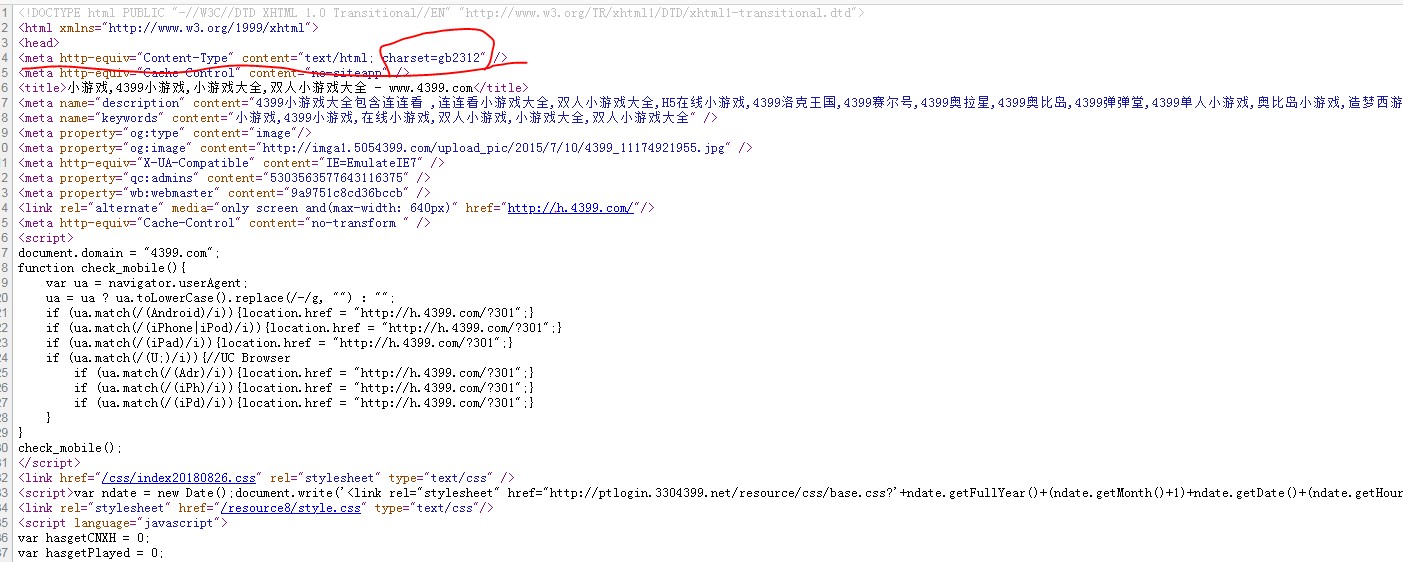 编码为gb2312
编码为gb2312
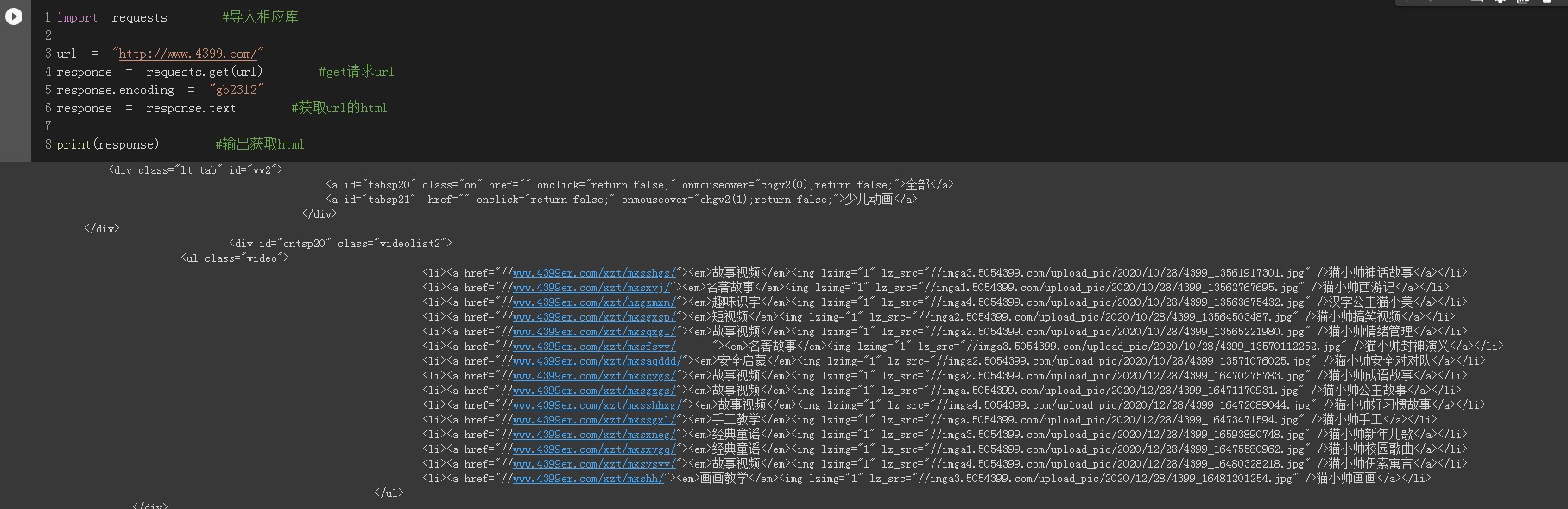
正则表达式(re库)
常用符号
| . | 匹配任意单个字符(不包括换行符\n) |
| \ | 转意字符(改变字符原来意思) |
| \d | 匹配一个数字字符,也可用[0-9] |
| \D | 匹配一个非数字字符 |
| \s | 匹配任何空白字符(空格,制表符等) |
| () | 匹配括号内内容 |
| \W | 匹配任何非单词字符 |
| * | 匹配前一个字符0或无限次 |
| + | 匹配前一个字符1或无限次 |
| ? | 匹配前一个字符0或1次 |
| [...] | 对应字符集中的任意字符([pjc]ython,匹配结果:python,jpython,cpython) |
sub()函数
用于替换字符串中的匹配项
re.sub(pattern,repl,string)
pattern:匹配的正则表达式
repl:替换的字符串
string:被替换的字符串

findall()函数
匹配符合的内容,并以list形式返回
re.findall(pattern,string)
pattern.string:同sub()
获取网站信息
- 发表于 2021-02-25 14:30
- 阅读 ( 1192 )
